Intro to Large Language Models and and their Future
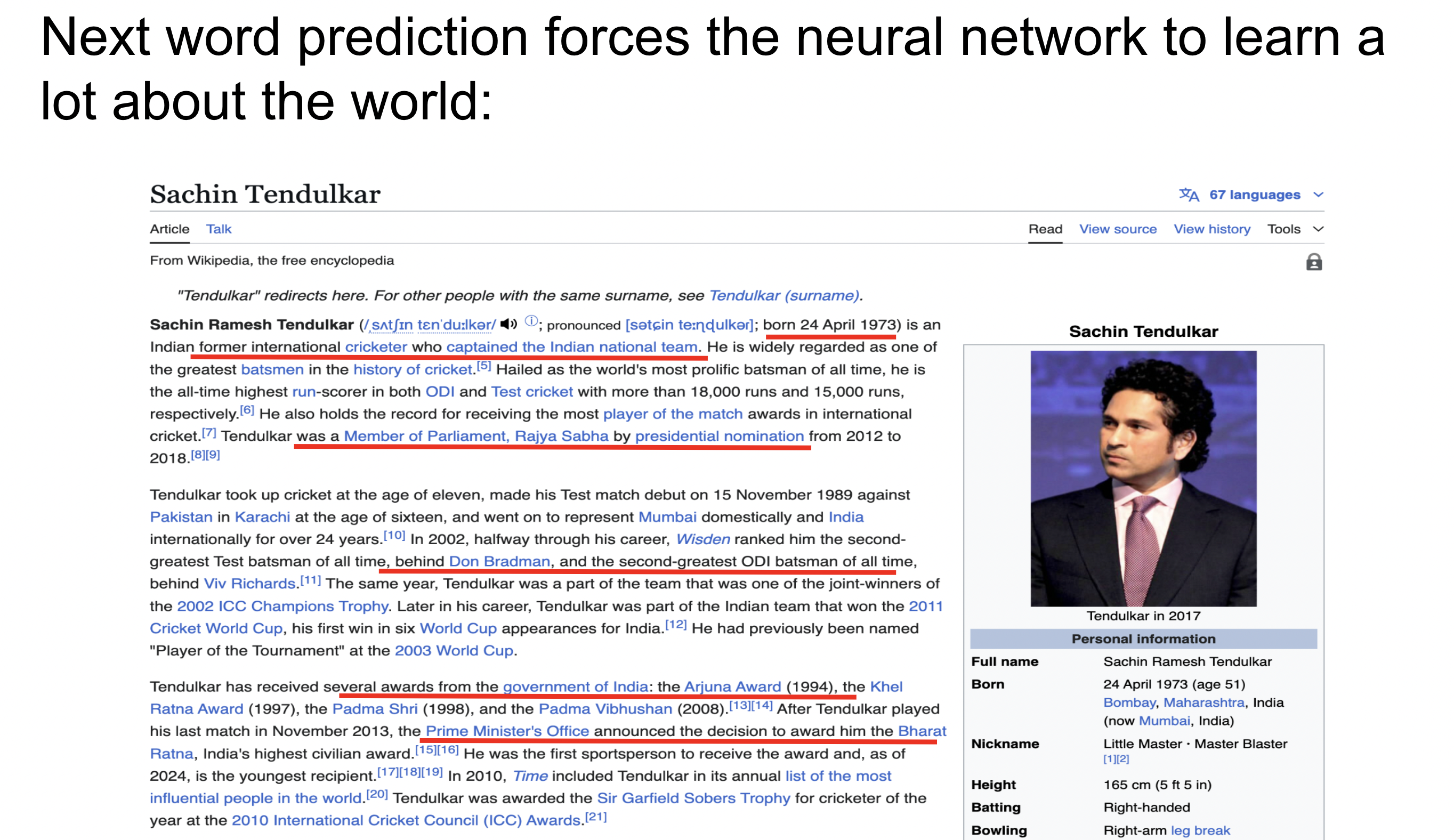
Modeling human language at scale is a highly complex and resource-intensive endeavor. The path to reaching the current capabilities of language models and large language models has spanned several decades. As models are built bigger and bigger, their complexity and efficacy increases. Early language models could predict the probability of a single word; modern large language models can predict the probability of sentences, paragraphs, or even entire documents. The size and capability of language models has exploded over the last few years as computer memory, dataset size, and processing power increases, and more effective techniques for modeling longer text sequences are developed.
We have come along a long way around
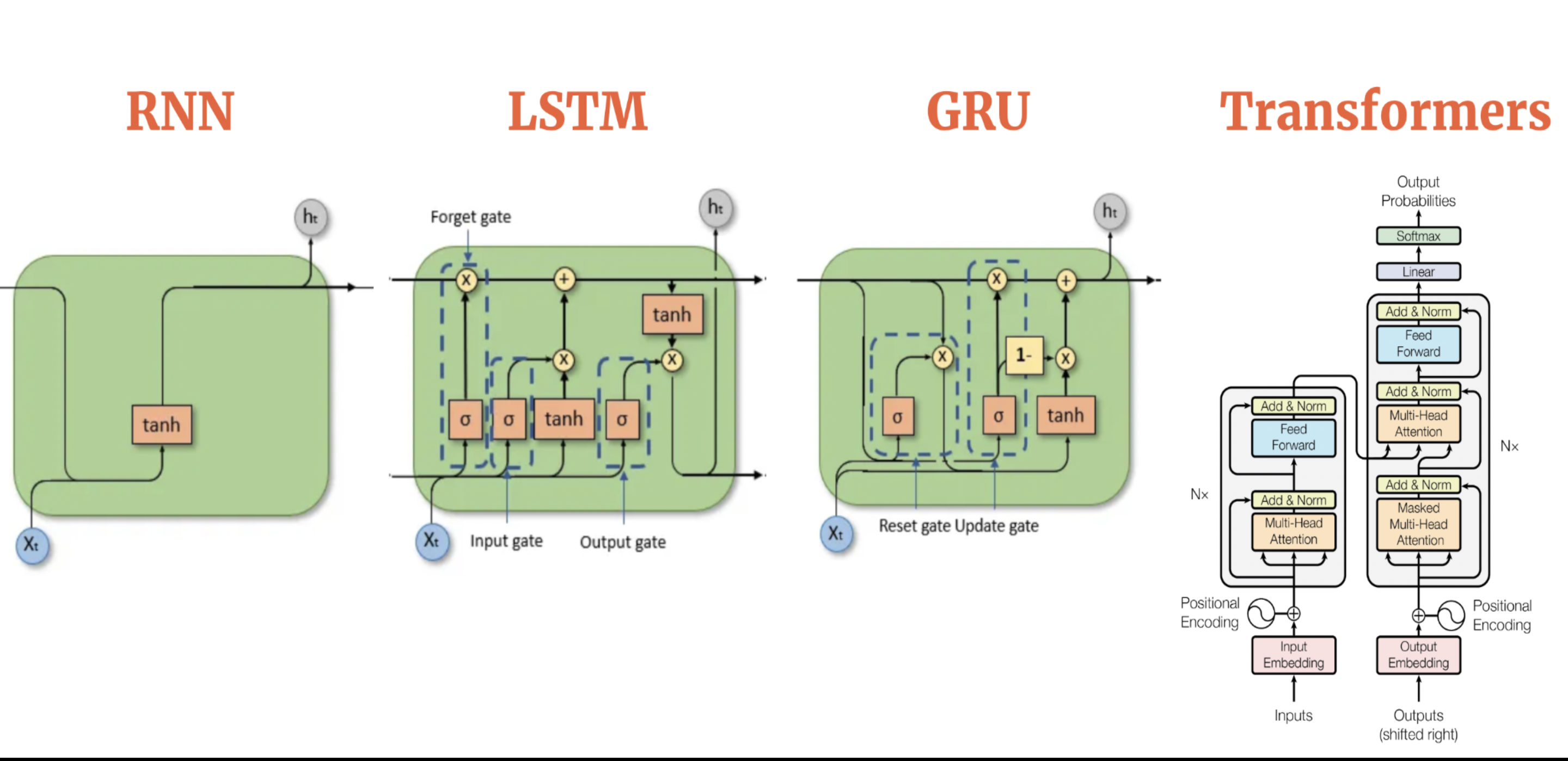
The shift from RNNs (Recurrent Neural Networks) to LSTMs (Long Short-Term Memory networks) and GRUs (Gated Recurrent Units) arose from the limitations of vanilla RNNs in handling long-term dependencies. RNNs suffer from vanishing and exploding gradients, making it challenging to learn patterns over extended sequences. LSTMs introduced gates (input, forget, and output) to regulate information flow, enabling them to retain relevant information over long sequences effectively. GRUs, a simpler alternative, reduced complexity by using fewer gates while maintaining comparable performance, striking a balance between efficiency and accuracy.
Despite their improvements, LSTMs and GRUs struggled with parallelization and scalability, leading to the advent of Transformers. Transformers abandoned recurrence in favor of a self-attention mechanism, which allowed models to capture dependencies across entire sequences simultaneously. This design enabled efficient training on GPUs and better performance on tasks requiring global context, such as machine translation and text summarization. Transformers also introduced positional embeddings to maintain sequence order information.
The scalability and effectiveness of Transformers were further realized with models like BERT and GPT, which leveraged pretraining on vast datasets. This approach revolutionized NLP, enabling models to achieve state-of-the-art results across diverse tasks. The Transformer architecture's flexibility and performance advantages have since made it the foundation for most modern NLP and generative AI systems.
The Timeline so far
2024 so far ..
The working of Neural Network and Next Word Prediction
A neural network is a computational model inspired by the human brain, designed to recognize patterns and make predictions. It consists of layers of interconnected nodes (neurons), each performing mathematical computations. In the context of NLP, a neural network processes input text by converting words into numerical representations (embeddings) and passing these through layers like dense (fully connected) or recurrent layers. These layers extract features and patterns from the text, transforming the input into a form that the network can use to predict or classify. Activation functions like ReLU or sigmoid introduce non-linearity, enabling the network to learn complex relationships.
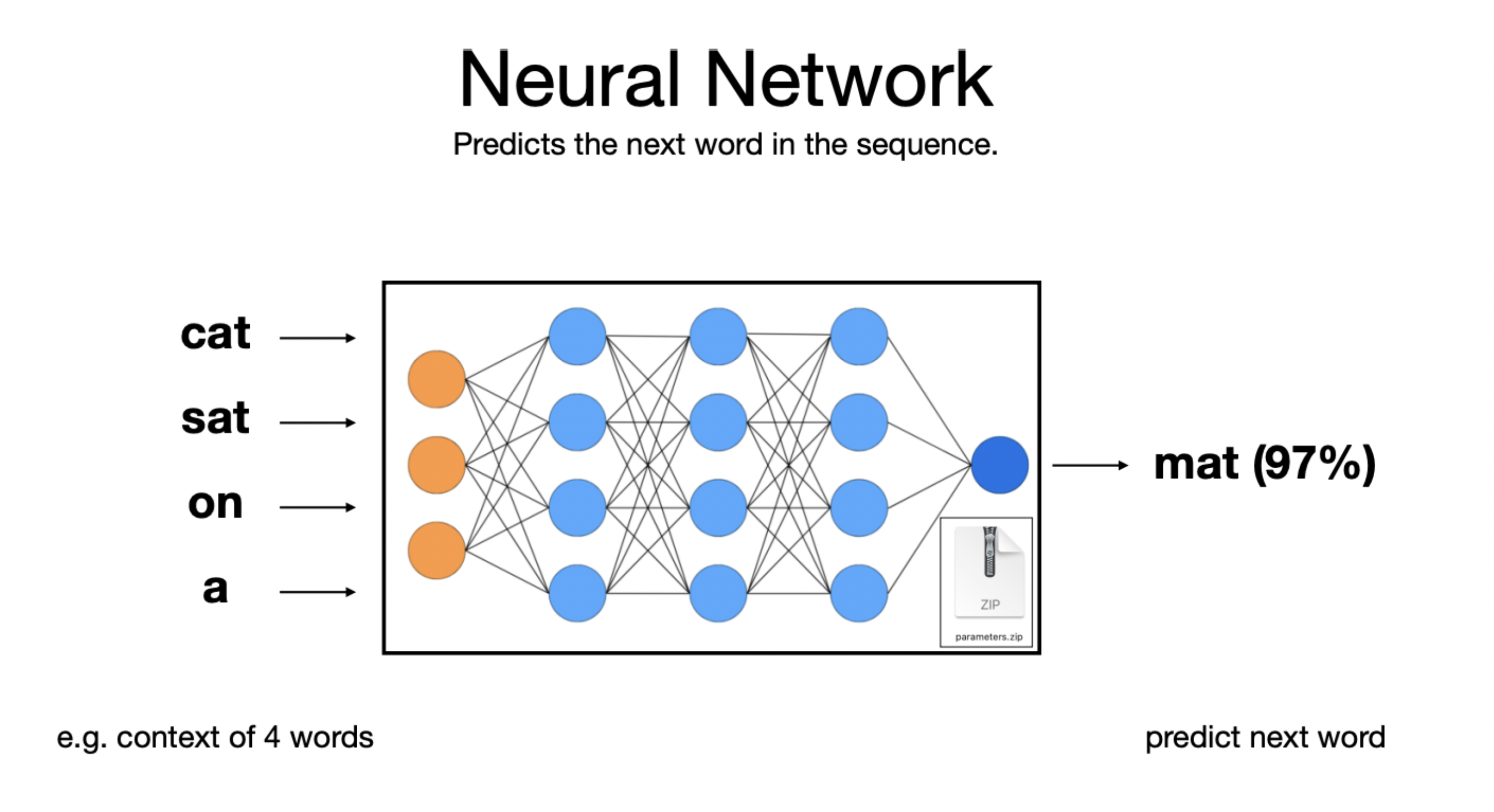
For next-word prediction, the neural network analyzes the context provided by preceding words. Models like Transformers use a self-attention mechanism to weigh the importance of each word in the input sequence, capturing both local and global dependencies. The output is a probability distribution over the vocabulary, generated through a softmax layer. The word with the highest probability is chosen as the predicted next word. Pretrained models like GPT further enhance this process by leveraging extensive training on large text corpora, enabling them to predict contextually appropriate words based on nuanced patterns and language understanding.
Attention comes into the game
Attention mechanisms became crucial in addressing limitations of traditional RNN-based architectures, particularly their inability to effectively handle long-range dependencies. Attention allows the model to dynamically focus on relevant parts of the input sequence when making predictions, regardless of their distance from the current processing point. For instance, in sequence-to-sequence tasks like translation, attention enables the decoder to "attend" to specific words in the input sequence that are most relevant to generating the current output word. This mechanism improved the performance of models like RNNs and LSTMs in tasks requiring context awareness.
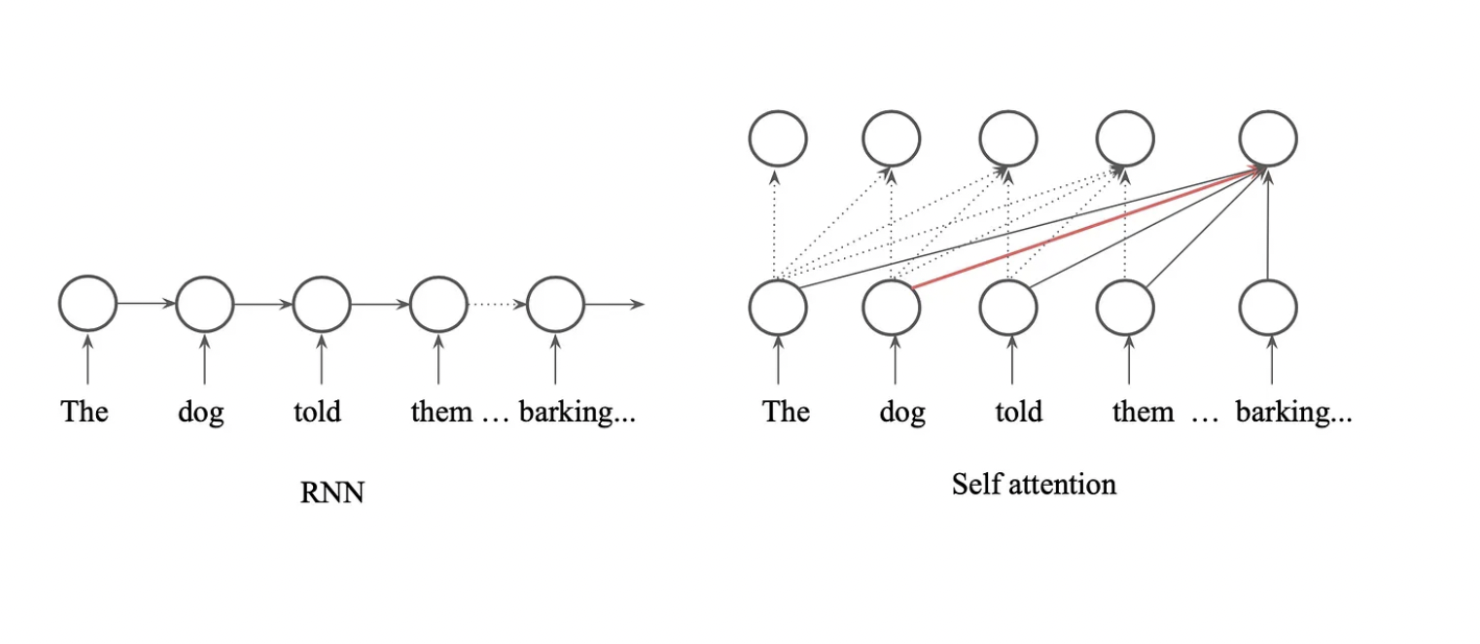
Self-attention, introduced with Transformers, generalizes this idea by allowing each word in a sequence to attend to all other words in the same sequence. This enables the model to understand contextual relationships globally, irrespective of word position. Unlike traditional attention, self-attention doesn't rely on separate encoder-decoder architectures; instead, it computes relevance scores across all positions in the sequence for every token. This approach, coupled with positional encodings to preserve word order, eliminates the need for recurrence, dramatically improving parallelization and scalability, leading to the success of models like BERT and GPT.
Hello LLMs
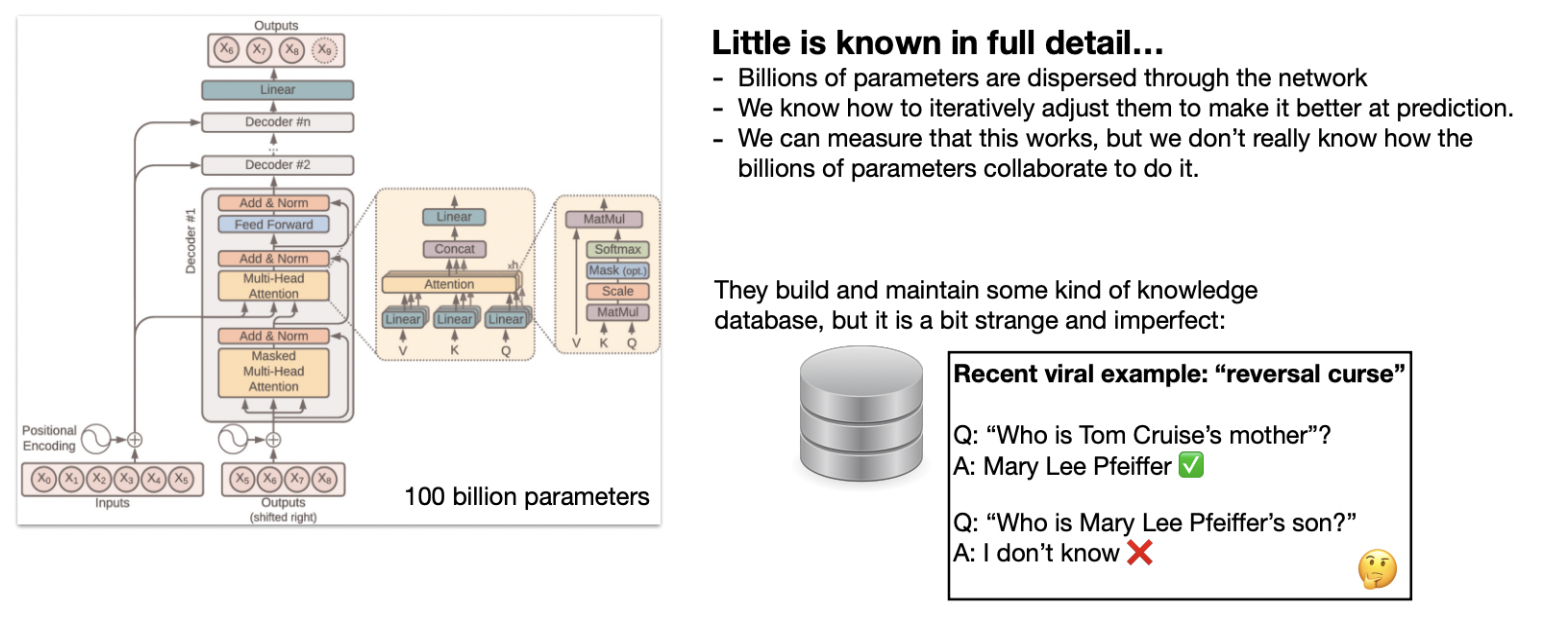
So overall, Large language models, like Transformers, rely on billions of parameters to process and predict language effectively. These models operate by breaking down text into smaller units (tokens) and leveraging self-attention mechanisms to focus on relevant parts of the input. They generate outputs by predicting the most likely next word based on the context provided. While they function as vast knowledge repositories, their ability to recall and reason over stored information is not perfect. For instance, they might answer specific questions accurately but fail when the same query is rephrased or reversed. This highlights both their impressive capabilities and their current limitations in understanding and consistency.
Pre-Training and Finetuning
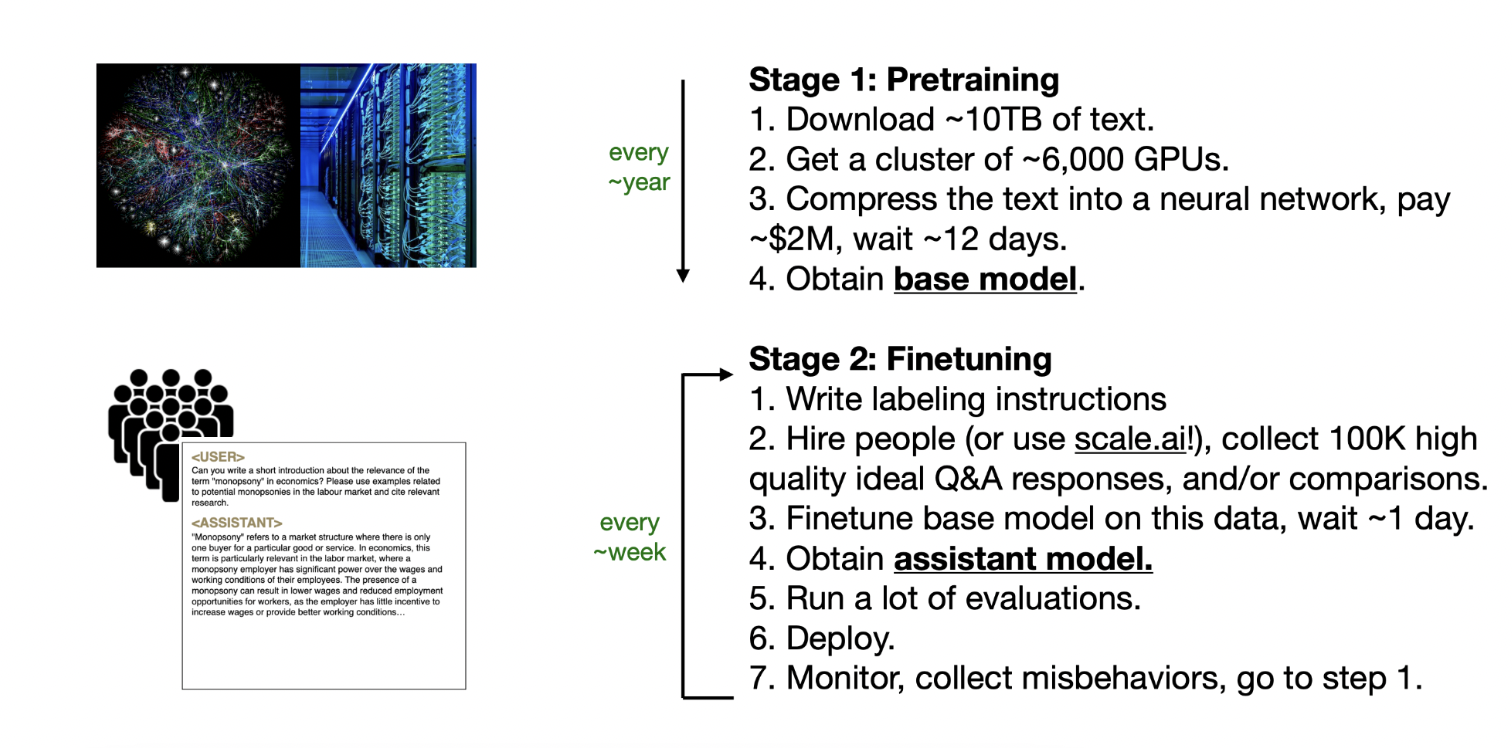
Pre-training is like teaching a baby to understand words and basic communication. The baby listens to people talk, learns what words mean, and starts understanding how to use them in everyday situations. This stage is about building a general foundation of knowledge, but during pre-training, we can't expect the baby to be ready for something complex like an interview, right?
Fine-tuning is when we take that basic understanding and prepare the baby (now older) for a specific goal, like answering interview questions. This involves teaching them how to structure answers, use professional language, and focus on the specific skills needed for the interview. Without the foundational pre-training phase, the fine-tuning phase wouldn't work effectively. Both stages are essential and build on each other.
Conclusion
Language models learn through a combination of pre-training, fine-tuning, and in-context learning. Pre-training captures general language understanding, fine-tuning specializes models for specific tasks, and in-context learning incorporates task-specific instructions to enhance performance. Understanding these approaches provides insights into the different stages and techniques involved in the learning process of language models, enabling their effective application across various natural language processing tasks.
Comments