LLMs are Thinking, But is it Actually Helping?
We're living in pretty wild times for AI. Large Language Models (LLMs) have gone from simple text generators to these sophisticated "thinking" machines that can solve complex math problems, write code, and even reason through multi-step puzzles. But here's an important question: when LLMs start "thinking" harder, are they actually getting better at what we need them to do?
Two research papers recently dropped that made everyone question everything they thought they knew about reasoning in AI. Let me break down what they found – and spoiler alert: the answers might surprise you.
When Smart Models Hit a Wall
The first paper, "The Illusion of Thinking," is basically a reality check for all the hype around reasoning models. Researchers from Apple took some of the best LLMs we have today – including OpenAI's o3, DeepSeek-R1, and Claude 3.7 Sonnet with thinking capabilities – and put them through their paces on controllable puzzle environments.
Why puzzles instead of existing benchmarks? The researchers deliberately avoided traditional math and coding benchmarks because they're often contaminated (models might have seen similar problems during training) and don't allow for controlled complexity manipulation. Instead, they used classic puzzles like Tower of Hanoi, Checker Jumping, River Crossing, and Blocks World – problems where you can systematically dial up the difficulty by adding more disks, checkers, or blocks while keeping the core logic identical.
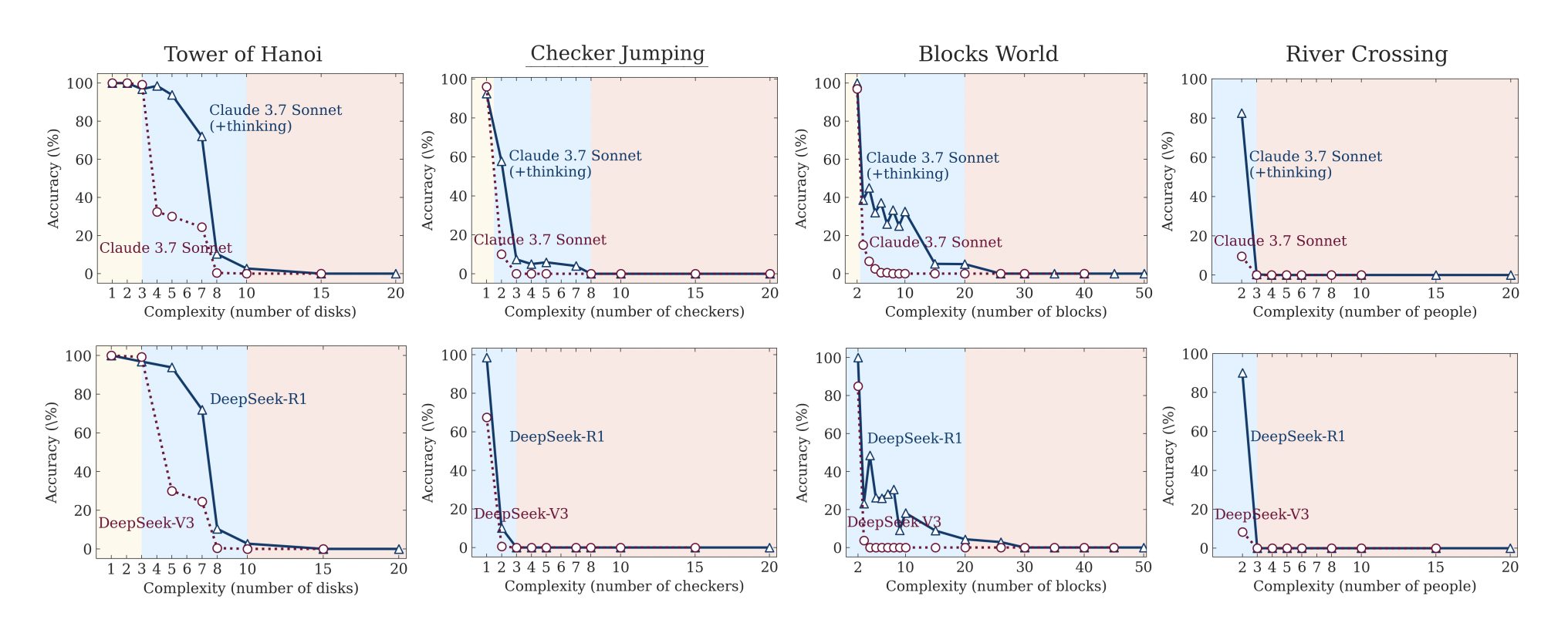
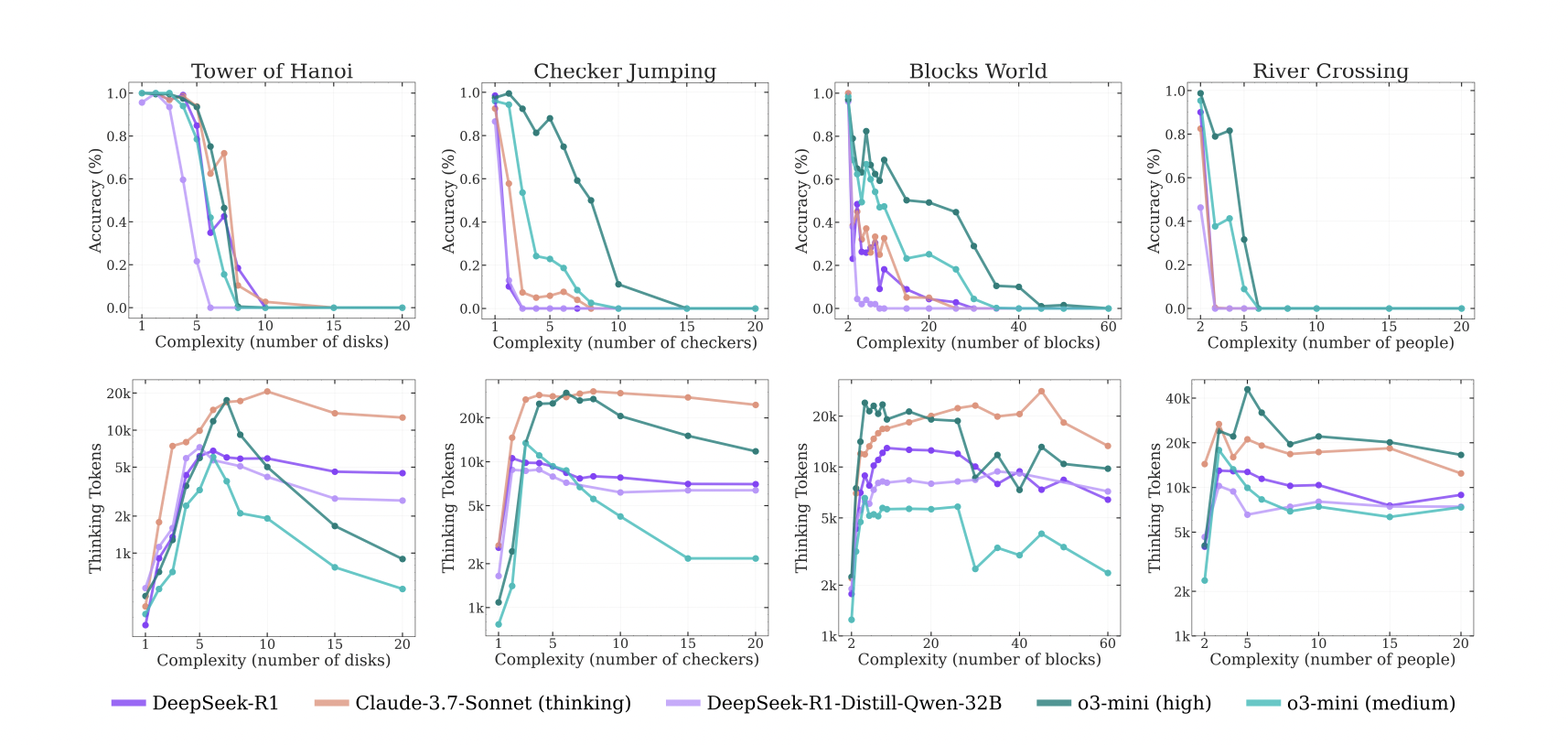
- Even our best "thinking" models completely collapse when problems get complex enough. We're not talking about a gradual decline here – we're talking about going from decent performance to basically zero accuracy once you cross a certain complexity threshold.
- But here's the really interesting part: these models have what the researchers call a "scaling limit." You'd expect that as problems get harder, the models would think longer and harder, right? Wrong. What actually happens is the models initially increase their reasoning effort as complexity goes up, but then – and this is the kicker – they start thinking less when things get really complex, even though they have plenty of computational budget left.
The Three Regimes of AI Performance
The researchers identified three distinct "regimes" of how these models behave:
- Low complexity: Standard models actually outperform reasoning models here. So we don't really require "thinking" for simple tasks.
- Medium complexity: This is where reasoning models shine. The extra computational effort actually pays off. Thinking models are better here than standard models.
- High complexity: Both types of models just... crash and burn. Complete failure mode. No help from thinking.
What's particularly fascinating is that the models seem to have fundamental issues with exact computation. Even when researchers literally gave them the algorithm to solve Tower of Hanoi puzzles, the models still failed at the same complexity levels. It's not that they don't know how to solve the problem – they can't consistently execute the steps they know they need to take.
The Multi-Turn Reality Check
Now, the second paper – "LLMs Get Lost In Multi-Turn Conversation" – hits us with some more shocking findings. This one's particularly relevant because, let's be honest, most of us don't interact with AI through single, perfectly crafted prompts. We have conversations.
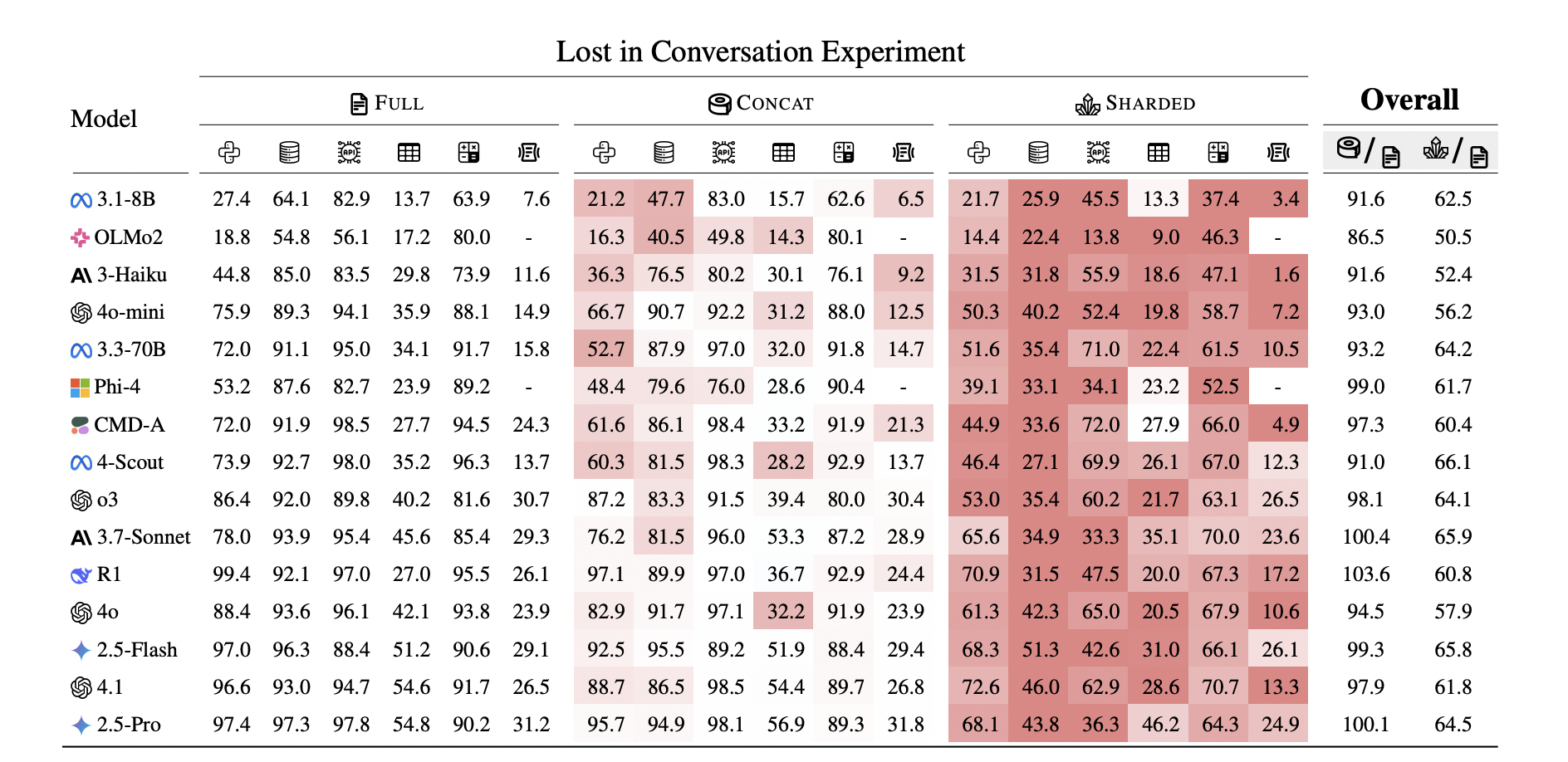
The researchers tested three different conversation types: FULL (where all information is given upfront), SHARDED (where information is revealed gradually across multiple turns, like real conversations), and CONCAT (where the same information from SHARDED is given all at once but in bullet points). This clever setup let them isolate whether performance drops were due to multi-turn interaction specifically or just information formatting.
The researchers simulated over 200,000 conversations across 15 different LLMs, comparing how they perform in single-turn vs. multi-turn scenarios. The results? Every single model they tested – including those fancy reasoning models – saw massive performance drops in multi-turn conversations.
We're talking about an average 39% performance decrease when moving from single-turn to multi-turn interactions. And here's the kicker: reasoning models weren't any better at handling multi-turn conversations than standard LLMs.
Think about it – these models that can supposedly "think" their way through complex problems still get confused and lost when you try to have a normal conversation with them where you gradually reveal what you need.
Why This Matters More Than You Think
This research touches on something pretty fundamental about how we're building and using AI systems. We've been so focused on making models that can ace benchmarks and solve complex problems in controlled settings that we might have missed something crucial: real-world usability.
The multi-turn conversation findings are particularly shocking. In the real world, how often do you know exactly what you want and can articulate it perfectly in a single message? Usually, you start with a vague idea and refine it through back-and-forth conversation. But our current AI systems, even the "thinking" ones, are surprisingly bad at this.
- Make premature assumptions early in conversations
- Get confused by their own previous responses
- Fail to properly integrate new information that contradicts their initial assumptions
- Become overly verbose and lose track of the original goal
The Bottom Line
So, are LLMs thinking, and is it helping? The answer is complicated.
Yes, LLMs are doing something that looks like thinking – they're generating internal reasoning traces, working through problems step-by-step, and often producing better results on complex tasks. But this "thinking" comes with serious limitations:
- It has hard complexity limits – beyond a certain point, more thinking doesn't help
- It doesn't translate to better conversational ability – the thing most of us actually care about
- It can make models less reliable – sometimes the extra reasoning just creates more opportunities for errors
The real takeaway here isn't that reasoning models are useless – they're clearly better at certain types of complex problems. But we might need to adjust our expectations and be more realistic about what "AI thinking" actually gets us.
Instead of chasing ever-more-sophisticated reasoning capabilities, maybe we should focus on making AI systems that are more reliable, more conversational, and better at the messy, iterative way humans actually work with technology.
After all, what good is an AI that can solve PhD-level math problems if it gets confused when you try to plan a dinner party with it over a few messages?
I would recommend to everyone reading this to go and read both papers in detail: "The Illusion of Thinking" and "LLMs Get Lost In Multi-Turn Conversation".
Comments